
Data Integration with Snowflake
Varsha Diwan
Sep 29, 2021
Snowflake Data Transformation for Businesses
Introduction: ERP vs Data Warehouse
Snowflake Data Integration is a process by which a variety of data is collated into a unified system that adds value to any organization’s business operations. A Snowflake data integration solution aims to deliver a single source of truth to businesses and support data pipelines that provide this data. The management of any organization also needs ready data for their self-service reporting, to get a complete picture of their KPIs/metrics, customer journeys, market opportunities, etc.
In recent times, there has been an exponential change in the volume and nature of data created. More and more organizations feel the need to improvise their data-driven business to support data of any nature (structured, semi-structured, or unstructured) and build systems that are easier and scalable. Integration with semi-structured formats like Avro, JSON should be efficient with existing structured data. A data integration solution should be built in such a way that the data models within them are simple without any complex scripts.
Thus, the stereotypical definition of data integration has also evolved with time. It not only means collating data from disparate sources but also includes data migration, movement and management of data, data readiness, and automating a data warehouse. The key here is to choose the right data integration platform and tool to maintain and grow the business of an organization.
Integration Approaches
Though data integration has a wider scope, the most common approaches to implement any data integration projects are ETL (Extract Transform and Load) or ELT (Extract Load and Transform).
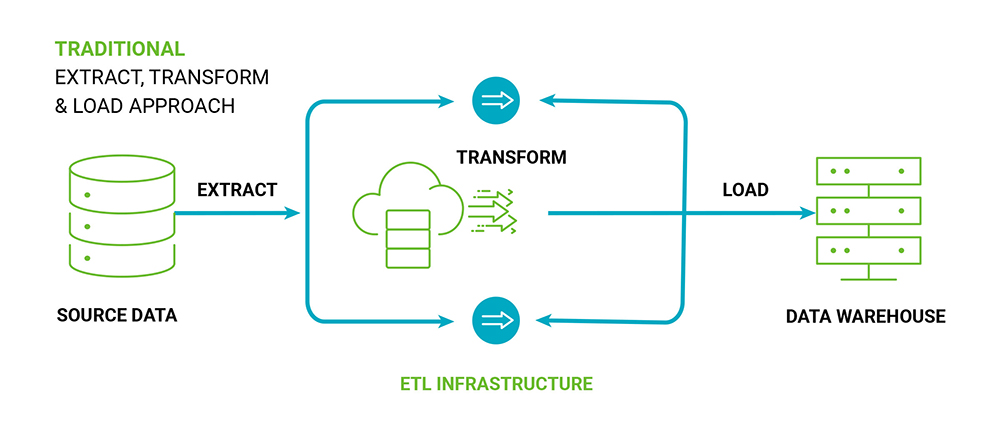
ETL is the most traditional way of implementation. It has been in the industry for a very long time now. Data is extracted from varied sources, transformed to suit business requirements, and then loaded into the data warehouse in such a way that the analytical needs of business users are resolved. The data warehouse is structured in such a way that reporting is fast, and a holistic and conformed picture of the organization is obtained. Overall, the ETL process is very compute-intensive, and it uses the computing capacities of the ETL server or engine. There are a lot of I/O activities like post and pre-SQL execution, string processing, numerical calculations, indexing, etc.
In ETL, the Extract process can be simple if only a single data source is used. As the number of (Snowflake) data sources increase, this process can become complex. Also adding is the nature of the (Snowflake) data sources. If there are no adaptors available for the source, then these sources cannot be integrated directly. Indirect ways must be used like modifying data manually or building CSV/text files. This will be time-consuming and may lead to human errors.
The Transform process is needed to change the format, structure, or value of the data and de-normalize it. New metrics/KPIs need to be calculated or existing ones combined or standardized for reporting purposes. The transformation process can be very resource-intensive and costly. It can also take longer than expected. As the volume of data increases, the transformation of data can take a longer time.
The Load process is inserting the transformed data into the data warehouse. The ETL approach can be used for smaller or moderate data volumes, where data transformations are more compute-intensive, and the nature of the data is structured.
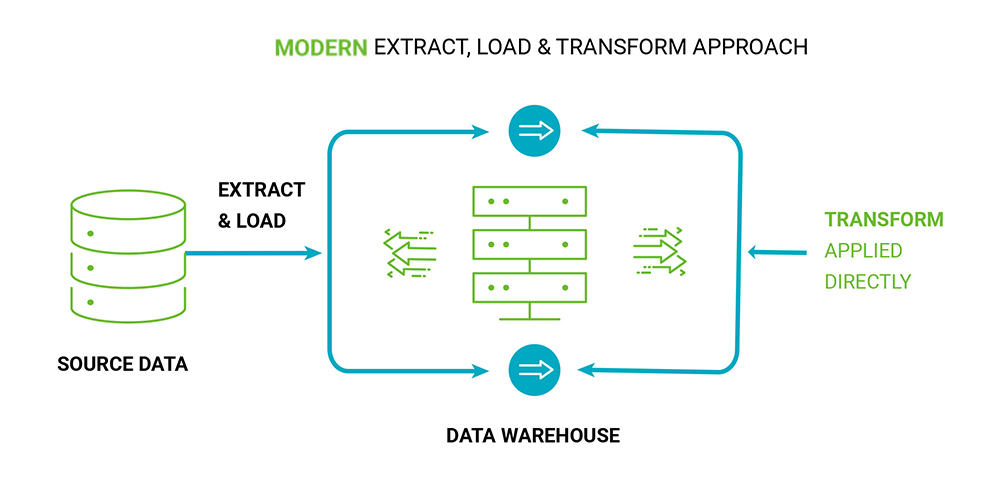
The ETL process though seems like a simple swap between ‘L’ and ‘T’, which is not true. The loading of data happens before it is transformed. Data is pulled as is the target database in the raw layer and then transformed. This way data is more accessible and handier while making transformations. For transformations, the computing power of the cloud data warehouse is used. The modern cloud data platforms like Snowflake, Redshift, Big Query, etc. are all columnar databases. They massively support parallel processing. Because of both these features indexing and finding a record becomes easy. Transformations can be carried out parallelly leading to quicker results. The ELT process is better suited to the needs of companies that operate with a variety of data formats (structured, semi, or unstructured) and for larger data lakes. With this design, infrastructure costs are reduced as there is no need for powerful databases and ETL servers. Workloads can be simple, and data can be migrated quickly and made available for transformation. Only the required amount of data can be transformed
Traditional ETL workflows have serious limitations. They are not scalable. As the data volumes increase, workloads become more complex. More IT resources are consumed creating bottlenecks and thereby creating a negative impact on the business. The business must wait when workloads are running, reporting becomes slow, and users see stale data. Refresh cycles are planned where there is a concentration of business users so users in other parts of the globe tend to see old data. This can lead to incorrect decisions owing to outdated, incomplete, or inaccurate data.
Snowflake – A Data Integration Platform
Developing a traditional warehouse and its maintenance was always on a higher end. Even though the infrastructure costs were reduced maintaining the warehouse, increasing the volume of data did cause an overhead. With the advent of cloud data warehouses, there was a change in this scenario. Snowflake Integration is the most rapidly upcoming cloud data platform.
Snowflake is a cloud data platform that is available as Software-as-a-service (SaaS). It has a pay-as-you-go model. Snowflake can be hosted on cloud platforms such as AWS, GCP, and Azure. Snowflake has a unique architecture. Cloud services, storage ( storage integration snowflake) And compute are all separate layers in Snowflake. This eliminates the architectural complexity so one can run multiple workloads parallel without facing any resource contention.
Snowflake Data Warehouse separates compute from storage (storage integration snowflake) hence data loads can continue to run on virtual warehouses without any interference with the business users who are retrieving data for their reporting purposes. It is an elastic cloud data platform which means it can automatically scale up and down to strike a balance of performance vs cost. Snowflake also supports multi-cluster architecture which means that it can add resources to manage user and query concurrency needs during peak hours. All these have eliminated the resource contention issues of a traditional data warehouse.
Snowflake Integration provides easy features of data sharing and masking that can be a great benefit to organizations. Data can be easily shared between consumers and providers complying with the data privacy regulations like GDPR and CCPA.
Snowflake’s cloning and time travel features are a developer’s delight. One can create multiple clusters for each environment that can be initiated only if needed to move code to production. In case of any failures, historical data can be retrieved using time travel and fail-safe. Developers can pull out data as old as 90 days depending on the Snowflake edition.
Snowflake Integration Platform can be used to build solutions for data warehousing, data lakes, data engineering, data science, data application development, and securely sharing and consuming shared data in various domains like Finance, Healthcare and Life Sciences, Retail, Advertising, Education, etc. With these features, Data Integration in Snowflake Warehouse has been consistently showing an upward trend in the number of deployments in various domains.
How Data Integration Works in Snowflake?
Snowflake not only acts as a cloud data platform but also supports the transformation of data while loading it. Some of the features that Snowflake provides are -
- Bulk load using COPY command – Data can be loaded from local files or cloud storage external to Snowflake. It supports multiple file formats like CSV, JSON, Avro, Parquet, XML, etc. Snowflake also provides various data conversion functions while using the COPY commands
- Data types – Snowflake Integration Platform supports a rich set of data types like numeric, string, date-time, logical, semi-structured like variant, array object, geo-spatial data types, and unsupported like a blob, clob.
- Stored Procedures – The native Snowflake SQL can be extended with Javascript to write stored procedures. Combining both SQL and Javascript has some benefits like
- Procedural logic (like branching, looping)
- Error handling can be done
- SQL statements can be dynamically created and executed
- Role-based execution of a procedure
- Streams – This object helps track the changes made to tables including inserts, updates, and deletes, as well as metadata about each change. This is Change Data Capture (CDC) which is a lifeline of data warehouse implementation. A changed table is made available to the user with the metadata columns indicating the type of DML operation.
- Tasks – Once the code is deployed to Production, CI/CD pipelines are needed to automate the data ingestion process and scheduling it on regular basis is needed. For Data Integration with Snowflake tasks can be created, and dependencies can be set so that once the master task is triggered all the downstream tasks are executed in a chain reaction.
- Snowpipes – To load data continuously, Snowflake provides Snowpipes to enable loading data from files as soon as they are available in stage. Data gets loaded in micro-batches and is made available to the users
But along with these features, as a developer, we observe that Snowflake does not provide the below features –
- Connectors to other data sources – Snowflake does not provide any connectors for applications like Salesforce. To ingest data from these applications, API calls must be made, and data has to be procured in the form of files into external stages to load it into Snowflake
- Email notification – Email notification is not available to intimate users of failures and successes of jobs that are running in Snowflake Integration Platform.
But these drawbacks can be overcome by using ETL/ELT tools available in the market and ingesting data in Snowflake using them.
How to choose an ETL tool?
Choosing the right ETL tool is key in data integration projects. Data Integration with Snowflake supports both transformations during ETL or after loading (ELT). Snowflake works with a wide variety of data like structured, semi-structured, and unstructured. There are several tools available that can plug and play with Snowflake. Some of the factors that need to be considered here are –
- Paid or Open-Source: The cost of the integration tool is a major consideration here. Paid tools will come with a cost, will be more structured but there will also be a dependency of continued support on the tool. On the other hand, open-source tools are free, but evolving with time.
- Ease of Use: Some of the ETL tools are user intuitive and have a simple drag and drop GUI. Others encourage developers to write SQL or Python scripts to enable complex transformations in the ETL process.
- Adding/Modifying data sources – The data integration tools should support many data sources like applications, text-based, unstructured, blob, etc. The integration tool should have the flexibility to add multiple data sources
- Ability to Transform the Data: Transformations are needed to add business logics to your data before loading it into a data warehouse. Some data integration tools have a variety of transformations like expression, aggregation, joiner, etc. while others have limited or no transformations. Choice of tool can vary depending on the number of transformations needed in the data warehouse.
- Product Documentation: Documentation is a key factor in understanding the various properties and checkpoints while using any data integration tool. Comprehensive documentation of the ETL/ELT tool is good to have.
- Customer Support: Many cloud based ETL tools have 24*7 customer support. Their support desk helps in resolving data issues. Calls or emails can be sent to customer support to resolve them.
Some of the recommended cloud-based ETL tools are Fivetran, Boomi, Stitch, Matillion or open-source tools like Python, Kafka, or Spark. These connectors provide an interface for developing applications that can connect to Snowflake Integration Platform and perform all standard operations.
Fivetran – An overview
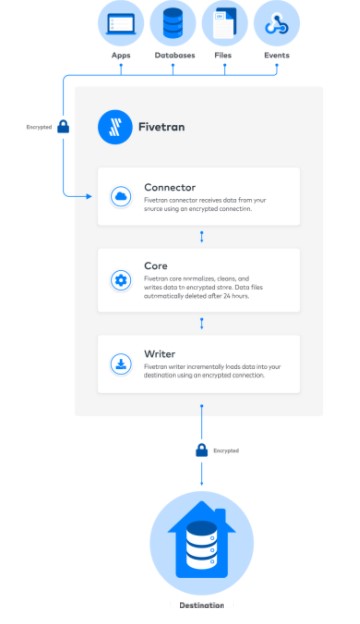
Fivetran is a fully automated cloud-based data integration tool. It provides a bunch of ready-to-use connectors for applications like Asana, Git, Facebook, Peoplesoft, ETP, CRM, etc, and databases like Oracle, SQL Server, Mongo DB, etc. It also seamlessly connects to Amazon S3, Google sheets, OneDrive, SharePoint, etc. As a developer one needs to configure connectors with basic information like (UserID, Password, and URL) and define destinations or target databases like Snowflake, Redshift, Bigquery, etc.
Fivetran has developed zero-configuration and zero-maintenance data pipelines that must accelerate the data load process. It automatically detects the changes in source schemas and APIs and adapts itself to ensure consistent and reliable data. Fivetran provides two types of transformations like SQL and DBT that can be scheduled and run on the destinations. Logs generated can be viewed on Fivetran dashboards.
Conclusion:
Snowflake Data Integration is a very complex and high-demanding process hence a robust cloud platform like Snowflake Data Warehouse and ETL/ELT tool are needed. Snowflake Integration Platform with its plethora of features is best suited for modern data integration. Data Integrations with Snowflake can be seamless and cost-effective. But it has its own limitations. Thus, the choice would depend primarily on the integration requirements, business users and commercial constraints of an organization.
Subscribe to our Technology Insights





About the Author

How Can We Help You?
Related Posts





