
How Cloud Computing Can Provide Competitive Advantage for Scientific and Industrial Computation
Binoy Das
Aug 18, 2022
High-Performance Computing in the Cloud for Scientific and Industrial Computing
Not very long ago, when I was working as an Enterprise Architecture advisor, I was increasingly being questioned about the then new phenomenon called "Cloud Computing", and what that means to enterprises. I had to educate my customers about how adopting Cloud Computing for their infrastructure is more than just a buy versus rent decision. At the same time, many customers were interested in knowing whether it would help them reduce their total cost of IT operations. Over time, I found a growing number of CTOs asking questions that reflect more forward-looking thinking, such as how they can use this technology to increase productivity, innovation, and reduce risk.
Today, for a vast majority of organizations running traditional enterprise workloads, the benefits of Cloud Computing are so evident that it is not a question of whether to adopt Cloud Computing anymore; instead, it is a question of how to go about it and under what timeline. However, there are some specialized workloads for which the benefits of Cloud Computing are still not clear. These are typically scientific and engineering workloads that require high computing power, often within a short time. The problem with traditional TCO calculation is that it fails to uncover the hidden costs of not leveraging Cloud Computing for such specialized workloads.
Cost challenges for AWS High-Performance Computing (HPC) in the Cloud workloads
Our pre-sales team fell into such a trap in one of our recent pursuits for a semiconductor chip design company. When the customer asked to see the return on investment in migrating their Electronic Design Automation workloads into Cloud, our teams used the toolset they use for traditional workloads. When they used the output from the Migration Evaluator tool and ran 1-, 3-, and 5-year ROI models, it showed that accounting for migration customer costs will still be red even after five years. That is why it is necessary to investigate other factors, to draw an accurate picture to show the cost of doing nothing.
HPC Cloud Computing workloads are required in tasks such as simulation of equipment behavior under real-world scenarios, modeling internal characteristics of complex systems such as semiconductor chipsets before costly manufacturing, and training state-of-the-art machine learning models for enhanced computer vision, or human-computer interface applications. These require compute capacity far exceeding those needed for running your everyday back-office, ERP/CRM systems, or web/mobile applications.
While it is true that the total cost of provisioning such computing power on the Cloud, exceeds even the high cost of acquiring specialized hardware in your data center, the cost modeling exercises commonly used implicitly assume a high utilization rate for on-prem hardware. It has been shown (in the Internet2 Global Summit presentation – HPC in the Cloud Computing) that to be cost competitive with Cloud-based HPC instances, your on-prem hardware must be operating at an 85% utilization rate. Given the transient nature of demand, companies run their expensive gears at a utilization rate that is much less.
Now consider the peak times in the R&D cycle when engineers and scientists are clamoring for that boost to their simulations. Since there is always a limit to how much capacity can be acquired within a fixed capacity location, many high-priority jobs compete to get their share of time under the sun, and your highly productive teams are now sitting idle. In the EDA industry, for example, in a 2-year design cycle for a particular chip, the design verification cycle is the most resource intensive, and the need for running the simulation and prototyping jobs peaks within the last 1-2 months of the design cycle. Therefore, any delay introduced due to backlog at this stage leads to a delay in handoff to fabrication, ultimately delaying the product launch. There is then an actual cost associated with not utilizing Cloud Computing in terms of lost potential revenue.
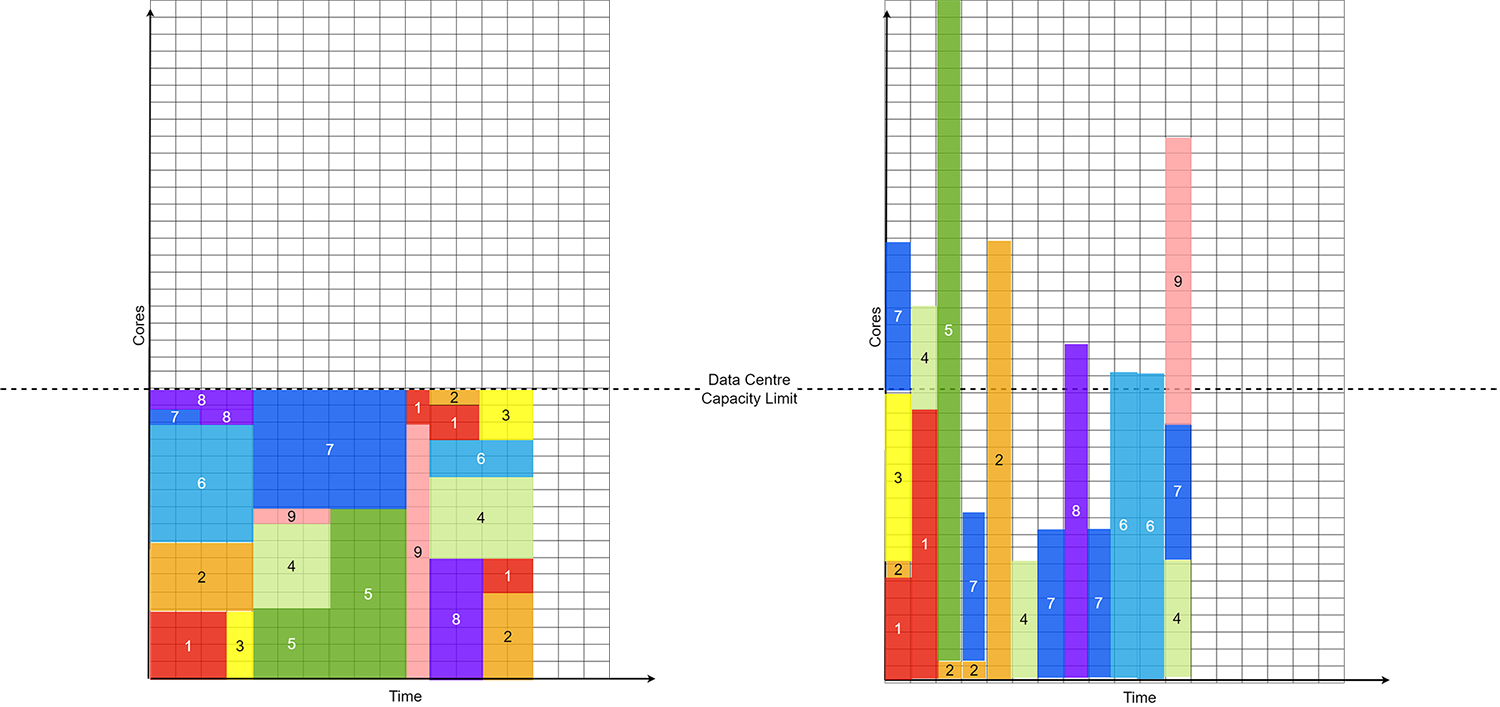
Scaling for HPC
In many such applications, proprietary softwares are used, that have prohibitive licensing costs. These licenses are often served from the license pool, and customers pay by the hour. This adds another dimension to the scaling benefits that can be achieved by spreading out the utilization, rather than having an HPC job acquiring one of these expensive licenses and being stuck in the queue. Think of getting stranded in traffic, riding in a cab, and the cab driver uses time-based metering – you’ll wish you had taken the trip when there was less traffic.
Now consider the rapid pace of innovation in the scientific, industrial research, and product development industries. In the semiconductor industry, for example, the scale of fabrication seems to get continuously reduced. Within two decades, nano-scale manufacturing has gone from 90-nanometer fabrication (as used in the 2003 model PlayStation 2) to 3-nanometers (with Samsung Electronics and Taiwan Semiconductors planning to release 3nm chipsets into the market by the end of this year). With such an explosive pace of innovation, there comes increasing complexity. For each reduction in nanometer scale, complexity increases at a scale of 10^n. This necessitates the need for a periodic refresh of infrastructure. While fixed infrastructure can be patched or updated, it’s only a matter of years before they fail to keep up with increased workload demand and hence become obsolete. However, with Cloud Native, HPC appliance customers never have to worry about this. When comparing Cloud-based and on-prem infrastructure for HPC Cloud Computing workloads, a direct comparison of hardware and software is just the starting point. It Is imperative to identify all these hidden costs and quantify them as accurately as possible. This helps us create individualized business cases for our specific customers. Given the customer’s size, maturity, and nature of business, we create the right plan for them to adopt Cloud Computing and get the most return on investment. It is never one-size-fits-all when it comes to such a significant commitment as establishing infrastructure for their most critical systems that cook up the secret sauce to their businesses.
One size does not fit all
While major hyperscalers, such as AWS, offer various services that can be put together to build a complete HPC platform on Cloud Computing, and although it might be the lowest friction way to get to Cloud, it is not practicable for customers other than those who are just starting and have a Cloud-native mindset from the get-go. For example, many of our semiconductor customers have already established EDA ecosystems that interface with design houses, researchers, and fabricators using toolsets that they have grown accustomed to. Such customers benefit most by seamlessly extending their workload into Cloud through Cloud-bursting when demand is high.
Cloud Computing providers, like AWS, provide core infrastructure services, but customers need help modernizing their operational toolchains to seamlessly use such services. For starters, they need to automate their infrastructure provisioning processing so that deploying an executable or submitting a batch job for execution also handles the infrastructure required to run the said executable, or job. Customers also need to upgrade their monitoring toolchains to collect better telemetry data from jobs running on Cloud. They must keep a close eye out for failures, be able to perform automatic remediation, and be able to keep and report accurate KPIs that would give a true picture of how their dollars are working. Above all, since security is paramount in running any closely guarded job on Cloud Computing, customers need a well-designed network with appropriate security controls.
To help our semiconductors customers, we often start by creating a secure Cloud Computing landing zone for them, with all necessary security controls and policies in place. Then we look for jobs on native OS and redesign them to run on standardized container platforms such as ECS or Kubernetes. From there on, we create infrastructure automation scripts that can take these containerized workloads and put them onto any Cloud within seconds, including those obtained temporarily, say with spot pricing. We can dramatically reduce the cost of running these AWS HPC jobs using spot pricing. Since the availability of computing varies on time-based demand, the caveat is to be able to pause and resume a job gracefully. So, we build cost-effective storage using native Cloud Computing services, such as AWS S3, to store sessions and state data.
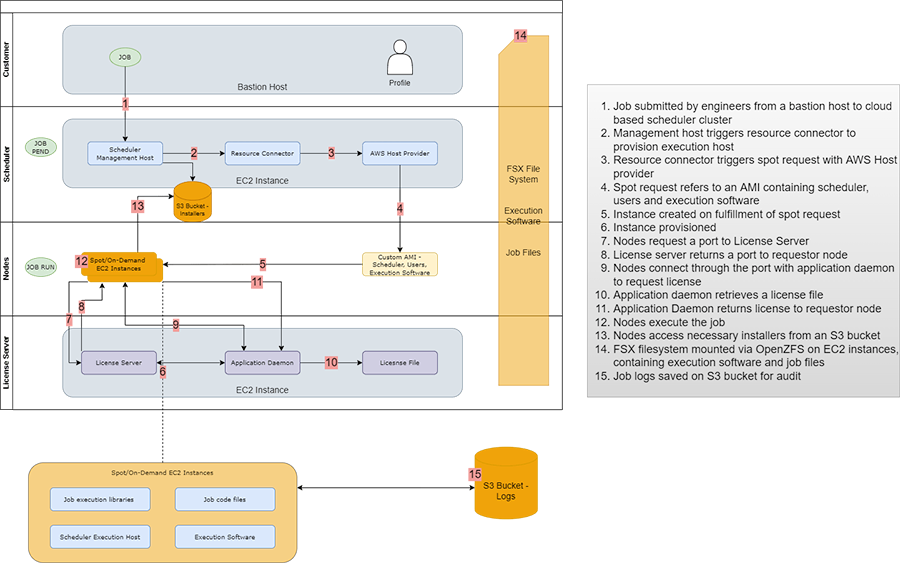
Conclusion
Over time, we have developed a reference architecture that allows researchers to submit HPC jobs using their familiar toolsets. The solution then procures the required infrastructure by deploying the container on existing on-prem racks or on Cloud, depending on availability. This results in an almost instant execution of submitted jobs, with no backlogs. It is an immense competitive advantage to our semiconductor customers, going after tight product version cycles such as 18 months’ for computer chips, or nine months’ for mobile chips.
To learn more about our services, visit https://www.jadeglobal.com/cloud-infrastructure-services
Subscribe to our Technology Insights





About the Author

How Can We Help You?
Related Posts



