
How to Design HA/DR Strategy - Microsoft SQL Server
Kundan Gaikwad
Sep 18, 2020
Microsoft SQL Server is the core database platform for a majority of today’s business-critical applications and it has several built-in features that you can use to protect your mission-critical applications and data from disasters and extended outages and keep it highly available.
This blog introduces High Availability (HA) and Disaster Recovery (DR) strategies for Microsoft SQL Server.
What is HA/DR:
High Availability (HA) provides a failover solution when a server, or database fails. Disaster Recovery (DR) provides a recovery solution across a geographically separated distance when a disaster occurs that causes an entire data center to fail.
Developing a HA/DR strategy can be challenging. Microsoft offers several possible HA/DR options, but which you choose will depend on your company and business requirements.
The very first thing to know is RPO & RTO to design High Availability (HA) and Disaster Recovery (DR) strategies.
- RPO stands for Recovery Point Objective: In simple terms, you can think of RPO as a measure of how much data acceptable to lose. Basically, the data loss in seconds/minutes. The time gap between last committed and most recent data recovered depending on the amount of damage the database suffered when disaster hit, recovering might take a lot of time.
- RTO stands for Recovery Time Objective: Again, in simple terms, you can think of RTO as a measure of how much downtime is acceptable by the company, or how quickly must the data be made accessible again.
Once you have sorted out all the requirements and limitations then it is time to begin reviewing the technologies to determine if it’s going to be possible to meet the SLAs within the existing limitations or not. One of two things can happen at this point, the requirements may be revised to work within the available limitations, or they can be prioritized to determine the order of importance for the design.
Available Solutions:
Backup and Restore
It sounds simple, but backing up the databases is the simplest, most cost-effective choice in a DR solution. Backup database is available in all editions of SQL Server. In Express edition, it is hard to automate the backups as there is no SQL Agent functionality.
Backups are great, but at the time of actual disaster, to restore them is the critical part.
You should be backing up and test restoring your databases regularly.
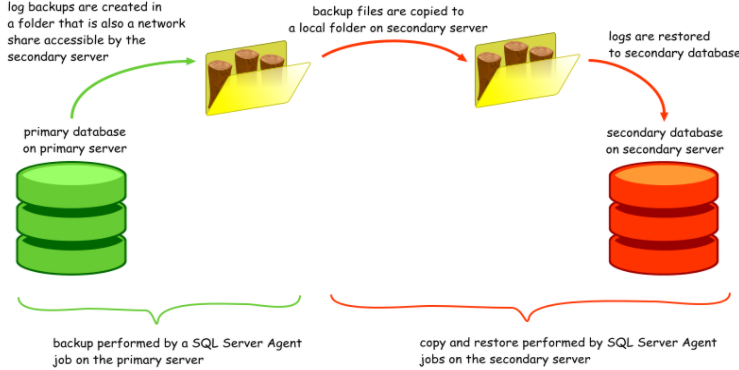
Log-Shipping
As name suggest, shipping of transaction Log backup files from 1 server to another and restoring them. It is just a Backup-Copy-Restore automated process with the help of SQL Server agent jobs. Alert jobs are also created to let you know when log-shipping gets behind for monitoring purposes. But the basic concept is that every 15 minutes a T-log backup is taken, then copied to another server, then restored there.
In LS, you can set up the Secondary server to be read-only between restores. You can have multiple secondaries.
This is database level only, so Logins, jobs, etc. are not copied.
You need to be familiar with File shares, UNC paths, permissions settings, etc. to set LS up.
Log Shipping is DR only, not HA unless you write a bunch of scripts to detect an issue, catch it all up and repoint your applications to the new Primary.
 Database Mirroring
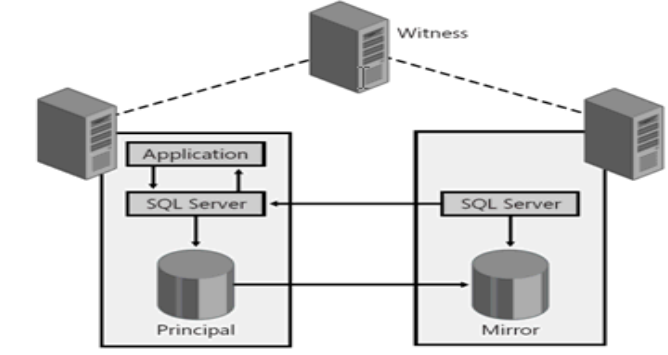
Database Mirroring
SQL Server also includes a technology called Database Mirroring that can provide HA or DR. It is limited to a single database and you can choose between synchronous or asynchronous mode. However, Microsoft has depreciated the Database Mirroring feature which means it will not be included in future versions of SQL Server. Instead, Microsoft recommends the use of AlwaysOn AGs or Basic AGs.
 Failover Clustering Instances
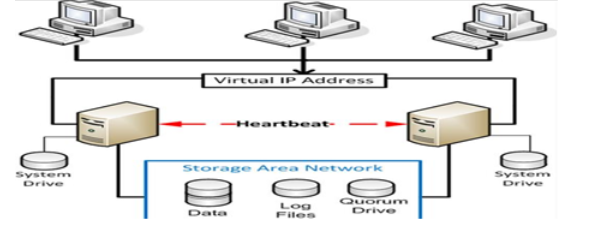
Failover Clustering Instances
Primarily a high availability (HA) technology, AlwaysOn Failover Clustering Instances (FCI) provide server-level protection from unplanned failure with automatic failover and no data loss. Like you might imagine, On Windows Server, AlwaysOn FCI requires a Windows Server Failover Cluster, and then SQL Server must be installed on each node using the SQL Server clustered installation option. On Linux, you need to user AlwaysOn FCI can be used for DR by using geo-clustering where the different cluster nodes are in separate physical locations sometimes in completely different regions. Windows Server 2008 and higher supports multi-site clusters.
 AlwaysOn Availability Groups and Basic Availability Group
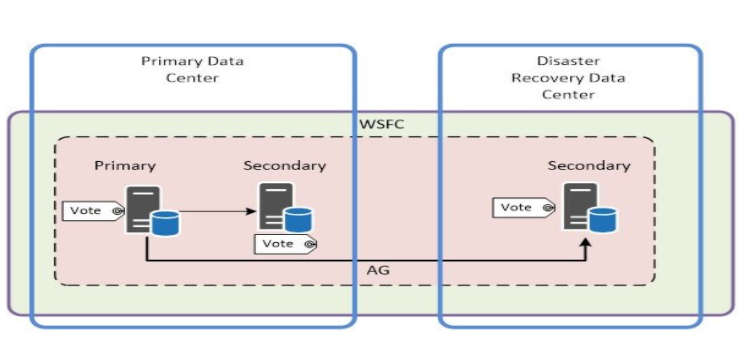
AlwaysOn Availability Groups and Basic Availability Group
AlwaysOn Availability Groups (AG) are the premier SQL Server HA and DR technology. AlwaysOn AGS protect multiple databases with automatic failover. They require a Windows Failover Cluster on Windows Server or Pacemaker on Linux. When a failure occurs on one server in a cluster, resources are redirected, and the workload is redistributed to another server in the cluster.
AGs are basically a much-improved version of Database-Mirroring technology. Multiple groups are allowed, Synchronous or Asynchronous, Manual or Automatic failover. Readable secondaries to offload reporting queries.
Standard Edition has a “Basic Availability Group” which has lots of limitations, chief among these being one database per group.
When set up correctly, AGs are both HA and DR for the user databases, with no single point of failure The licensing of AGs has changed a lot, so | won't get into it here... but you probably already know that Enterprise Edition licenses are expensive so need to plan accordingly
Subscribe to our Technology Insights





About the Author






