
Content Management Using Hadoop
Jade Consultancy Team
Jul 05, 2017
We live in a world of cloud computing, best-of-breed applications, and BYOX (bring your things). Companies are opening up to providing freedom and choice of technology and tools. Freedom to use tools and applications of choice shortens the learning curve and promotes focus on innovation and efficiency. But this freedom comes with a cost. Enterprises need strong technology infrastructure and processes to support various applications, tools, and platforms while ensuring security, privacy, and compliance.
Our experience of working with the publishing industry has let us observe this bitter-sweet truth firsthand. In the publishing world, content is generated by many internal and external contributors. In most cases, it is impossible to enforce the usage of single content management systems and ideation-to-publish processes. So companies end up generating a large amount of content from discrete systems in various formats. Commonly content being accumulated is a large amount of data, unstructured, in waves, and inconsistent.
Utilization of Hadoop Data Management for Efficiency
For efficiency and consistency in publishing quality content, it is very important to have a set of common formats for content and digital asset management. Common formats promote efficiency, modularity, standardization, and reuse of content and other digital assets. Big data platforms like Hadoop data management can come in handy for publishing firms to apply a layer of common formats and processes on top of a large amount of unstructured content they accumulate from discrete systems and individuals. The Hadoop data management Ecosystem provides the technology platform required to handle large unstructured content data to support enterprise-scale publishing.
At Jade Global, we have created a reference architecture to support and enhance the publishing process. This is based on our experience with companies dealing with a large amount of unstructured content from discrete systems based on the Hadoop data management ecosystem. This architecture covers the most commonly sought-after functions of the publishing process, like aggregation, filtering, curation, classification, indexing, standardization, modularization, and workflow. There are many more Hadoop data management Ecosystem components with potential usefulness for content management and publishing, but the reference architecture covers the most commonly used functions. Also, it is possible to slice ecosystem components to implement each function separately on top of Hadoop Core.
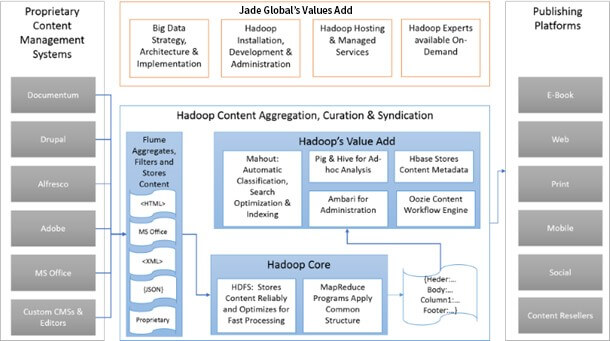
Core Functions of Reference Architecture
Aggregate:
Hadoop Flume Agent and Sink efficiently collect unstructured data from discrete systems. In a typical configuration, each source system is assigned a dedicated Flume agent, which will be configured to collect data in a format that the source system can provide. The beauty of Flume is that it supports various formats, so there is no need for changes in source systems. Also, at Jade Global, our team can create custom Flume connectors to collect data from unsupported proprietary systems. The function of Flume Sink is to apply a filter to incoming data and store it in Hadoop Distributed File System. A sink can be used to filter out data that is not needed for the further publishing process. Or it can perform simple transformation functions before storing content.
Storage:
Hadoop Distributed File System provides reliable and high-performance storage for structured and unstructured data. Because of high-performance access and support for unstructured data, HDFS is perfectly suited to store unstructured content from various source systems. Jade’s Hadoop team specializes in installing, administering, configuring, and maintaining Hadoop Core components like HDFS.
Standardize:
MapReduce is Hadoop’s data analysis, manipulation, and programming engine. It delivers high-performance data transformation capability with almost effortless programming. With MapReduce’s ability to read, analyze and transform a large volume of unstructured data at lightning-fast speed, it becomes a powerhouse of standardizing content in the format the enterprise publishing process requires. Jade’s specialists have experience developing MapReduce-based standardization processes, including removing unnecessary content (like CSS styling and HTML tags). Changing the content format from proprietary to industry standard open formats, consolidating content files by type of content, modularizing content for future reuse, duplicate identification & cleanup. Our passion and drive to explore better ways to transform unstructured data continue to deliver new ways to optimize MapReduce for our clients.
Machine Learning:
Mahout Machine learning platform is a high-speed and highly scalable self-learning platform that runs on top of Hadoop data management. Mahout’s most common use cases in publishing include automatically classifying content segments, identifying search tags for content segments, and automatically generating metadata for content. Automatic content classification on a large amount of unstructured data using Mahout can bring huge efficiency and standardization benefits to enterprises.
Search and Hadoop Metadata Management:
Like standardization, MapReduce can run high-speed search indexing and metadata creation jobs on a huge amount of data. At Jade Global, we have devised highly efficient MapReduce-based processes to generate search indexes from various open and proprietary sources. Also, we specialize in automatically identifying custom metadata based on the company’s requirements from unstructured discrete content sources. We also assist our clients in installing, administering, configuring, and maintaining the HBase database to store content metadata and other transaction information. HBase is a Hadoop data management-based column-oriented no-SQL database that delivers the convenience of a relational database with high scalability and lightning-fast performance.
Advantages of Reference Architecture for the Publishing Process
1. Freedom and Productivity:
Implementation of this reference architecture allows authors and contributors to use the platform of their choice for ideation, authoring, and packaging content. The reference architecture includes a standardization process, so the organization does not need to compromise security, privacy, and standards compliance while allowing discrete systems to generate content.
2. Common Formats and Processes:
The reference architecture supports standard publishing processes and formats. With high-speed standardization support, the reference architecture and Hadoop data management ecosystem allow organizations to define and enforce best practices and processes for publishing. Also, it allows for continuous optimization of the publishing process and formats to keep up with changing business and technology needs.
3. Automation:
The reference architecture and Hadoop data management Ecosystem enable an organization to automate large portions of the content publishing process with the flexibility of human intervention as needed. From content aggregation, standardization, classification, indexing, and search optimization to open standard publishing can be automated using the Hadoop Oozzie workflow engine.
4. Open Format Publishing:
This architecture promotes publishing content in open and industry-standard formats to achieve publishing flexibility to multiple platforms like web, print, mobile, social, or even content resellers. This allows publishing businesses to explore non-traditional revenue streams and innovative content delivery methods.
5. Time to Market:
Automation, standardization, process focus, and high-speed processing of large data enable businesses to publish content quickly. In today’s competitive world of content publishing, each second spent from ideation to publishing is critical for the success of content delivery, its popularity, and revenue generated from it. The reference architecture and Hadoop data management Ecosystem enable enterprises to achieve best-in-class efficiency for the publishing process.
Read the blog: Is MapReduce dead?
Subscribe to our Technology Insights





About the Author

How Can We Help You?
Related Posts





